Welcome to this edition of our Tools for Thought series, where we interview founders on a journey to help us think better and work smarter. Josh Nicholson is the co-founder of Scite, an award-winning platform for discovering and evaluating scientific articles.
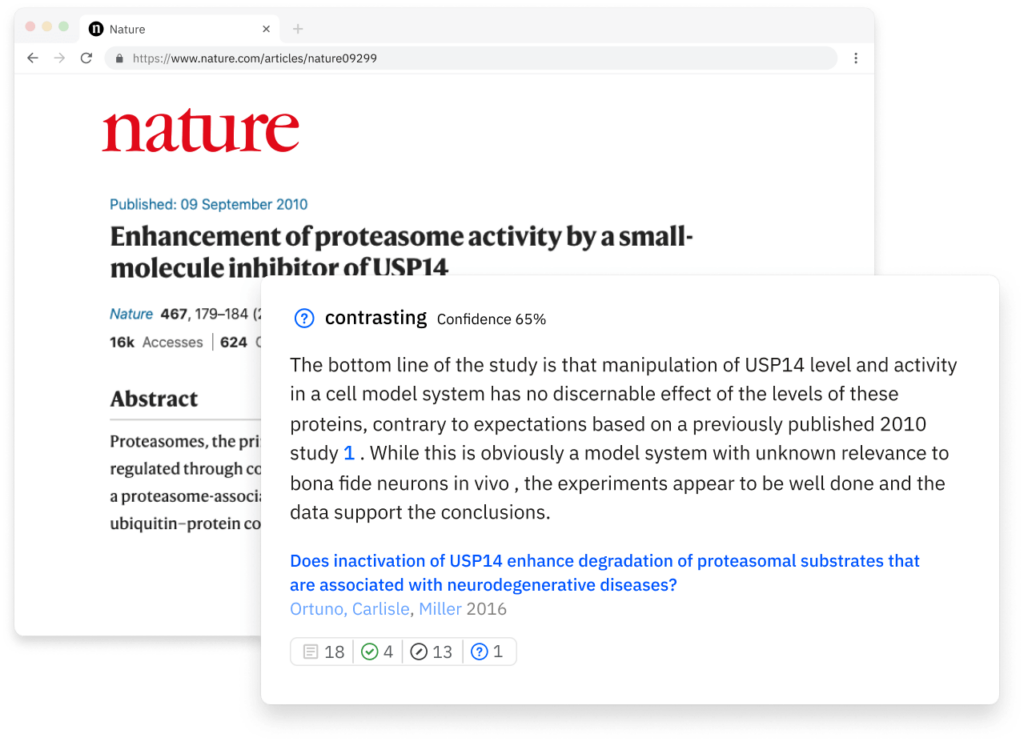
Scite allows users to see how a publication has been cited by providing the context of the citation and a classification describing whether it provides supporting or contrasting evidence for the cited claim.
In this interview, we talked about the nature of research, the research lifecycle, the problem of trustworthiness and reproducibility in science, how to navigate retractions, the importance of discoverability, and much more. Enjoy the read!
Hi Josh, thanks for agreeing to this interview! Let’s start with a big question. What makes scientific research so challenging to work with in the first place?
Thanks for letting me chime in! Scientific research is complex by nature. When I describe my work on aneuploidy and chromosome mis-segregation, almost immediately 99% of the population tunes out or can no longer understand me.
The terms used in scientific research are often specialized and while necessary to communicate accurately, can leave a lot of people lost. With that said, scientific research is amazing and affects everyone in some way.
There is research on how video games affect spatial reasoning, how Peppa Pig influences children learning English, and how SPG20 on chromosome 13 affects cytokinesis. Research touches all of our lives, mostly in a positive way.
I got into cancer research to try to understand the etiology of cancer better so that we as a research community improve the outcomes of cancer patients. My work now focuses on making all of research more understandable, accessible, and trustworthy so that people, whether they are a researcher or not, use research to make better decisions in their life and work.
Peppa Pig and chromosomes — you got a point. It’s an age-old problem. So, why do you think now is the right time to tackle that challenge?
With COVID-19 upending the world, we all fully understand how scientific research can impact our lives. Now with the rise of ChatGPT and other large language models, we all fully understand the need to be able to verify information online. Is that COVID-19 study trustworthy? Is that ChatGPT output factual?
Scite addresses these problems head on through the development of Smart Citations — citations that make it easy to see how any research paper has been cited, how any topic has been cited, and basically how anything is cited!
While Scite was born out of the frustration of researchers trying to determine if a study was reproducible or not, the use cases have been more than we could have imagined. One of the more exciting applications of our Smart Citations is validating the output that ChatGPT and other AI based tools are generating.
The timing of what we’re building couldn’t be better. People have been trying to build something like Scite since the 1960s, but failed because the technology just wasn’t there yet. And given the rise of ChatGPT as well as the general explosion in research volume in recent years, there’s a compelling need for more streamlined, efficient solutions to engage with the scholarly literature.

Agreed, the time is now. Next, can you explain how Scite actually works?
In one sense, you can think of Scite as like Rotten Tomatoes for research: take a paper, topic, author, etc. and easily read what research says about any of them.
Could those findings be replicated by others? Did someone discuss this piece of research in the Introduction section to give background to their own work, did they mention it in the Methods section because they used similar methods, or did they cite it in the Results section to compare their findings?
Without Scite, all this information is really hard to get because it requires you to read through hundreds, if not thousands of papers.
With Scite, you can easily see at a glance what the research says about any topic. We accomplished this by partnering with most major academic publishers, who give us access to the full-text of research articles.
Our system, which we’ve published the details of, is able to extract, link, and classify the citation statements–textual context that happens when citations are made in text– from articles and make that information available to our users.
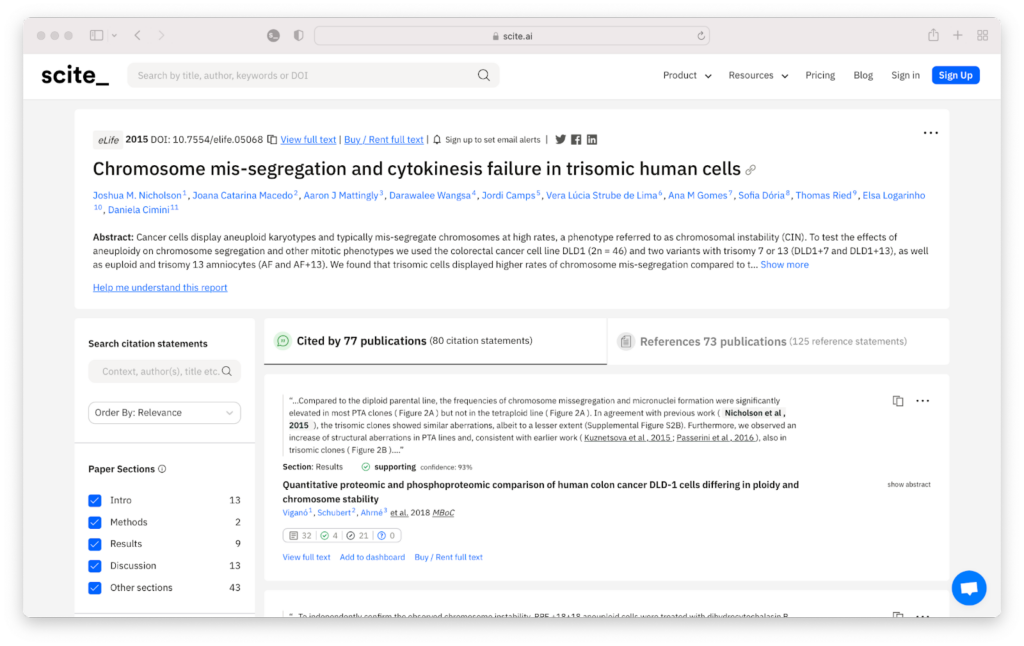
Of course, as we’ve developed the product, we’ve discovered other ways to leverage our unique data of Citation Statements to fulfill other needs — from our unique Citation Statement search experience to verifying claims made by ChatGPT.
Scite also allows users to look up any research topic directly. Can you tell us more?
One of the pivotal moments in our product journey was the realization that our database of Citation Statements could be searched directly. Typically, when we index those statements, we take the sentence where the reference was made and also include the sentences before and after. The resulting statement is long enough that it offers a good contextual overview. So, we designed a search experience around it.
It started by letting anyone query keywords against our database of statements. As a personal example, I live in Brooklyn and often think about the rising rents in New York. Well, it turns out you can query “Rising rents in Williamsburg” in Scite and we have a few Citation Statements that cover that exact topic!
One of our colleagues is a physician and travels for Doctors Without Borders. Part of his fieldwork involved the Rohingya people in Myanmar and he was curious what the rate of hypertension was in that demographic. It turns out Scite had answers.
There are a few things worth pointing out here. First, we’re not restricted to life sciences but have good coverage across fields including the social sciences. While the statements and sections are useful when deciding what papers to read, we enable you to chain ideas at the level of claims instead of papers.
Each citation statement from a paper makes one or more claims and has a number of other in-text references that we link by DOI. So when you’re reading a statement, you’ll see that the original authors cited e.g. 6 papers in-text which are likely related to the claims made in that statement.
You can click on each of those in-text references to see more information about those papers and quickly trace ideas. Chaining ideas like this creates a natural filter for relevance in the papers you read because they’re about the specific claims you’re interested in.
In addition to listening to users and developing a tool that helps meet their needs, we are also very focused on meeting our users where they are. We know how fragmented the ecosystem can be, so we have a free browser extension and Zotero plugin that researchers can add that shows our badge wherever they read and manage research. They can always click through to dig into it through Scite, but it’s often a nice integrity check that offers a little more information than a simple citation count.
What about evaluating that research? It can be incredibly time consuming to compare and contrast the literature.
Yeah, so properly evaluating research is time-consuming; you have to get the queries right to make sure you’re filtering for a relevant list of papers, then go through citation lists, abstracts, and even the full-texts (ideally) and track which ones are relevant and reliable for your review.
Sometimes you have access to proxies of quality like citation counts, social media mentions, and so on, but they’re not always the best measure of the most fundamental thing we’re worried about when reading a set of papers: how reliable are these claims, and can I base my ideas on them? And thinking of all the tabs and notes involved is nightmarish!
Scite is designed to streamline these tasks. I mentioned earlier that you could chain citations at the level of claims, and I think regardless of whether you start on our search or on a report page, this is a really special way of finding papers that are worth evaluating.
Even better is the fact that this workflow places more of an emphasis on the actual claims rather than things like citation counts, which improves the discoverability of lesser known authors or publications,gives you confidence that you’re actually being thorough, and offers a voice to more underrepresented groups in the field.
It doesn’t stop there, though. Often we do a literature review project and have to come back to update that information. Maybe in a few months or years. In that time, more research has undoubtedly been published and we’ve been juggling a bunch of other projects. Scite can reduce the cost of this context-switching through features like Custom Dashboards and Alerts.
A very typical use case is for researchers to sync their Zotero library into Scite — essentially the list of relevant DOIs, and set an alert to be notified when new citation statements are published about any of them. This makes new qualitative information — the statements — come directly into your inbox, so you can search for them or be notified when something relevant is published.
This is pretty commonly used for pharmacovigilance monitoring in pharmaceutical companies, or even individuals looking to be notified about new therapies or advances in a field that’s personal to them (think diabetes management).
A big challenge in research is how difficult it is to track retracted papers. How does Scite address this challenge?
Scite’s mission is to improve how researchers evaluate the reliability of research — whether it’s a reference in their manuscript or a paper or topic they come across. Besides reading any contrasting statements we’ve indexed about a paper, another quick check is to ensure it hasn’t received any retractions or other concerning editorial notices.
We have our own system for detecting these notices and surface it in a number of ways to ensure that users at different stages of the research lifecycle can make actionable decisions from it.
Retractions are part of a broader system in publishing around “editorial notices”. This is a mechanism for publishers to notify the community that there was some change about a publication — from small or big mistakes (e.g. Comments, Corrections, Errata) to evidence of fraud (typically manifesting in a Withdrawal or Retraction).
Though retractions are generally a healthy part of the broader publishing ecosystem, having a work retracted is typically a negative thing for both publishers and the involved authors.
You can check for a retraction by going to a publication’s landing page on the version of record, although different publishers vary in how they information about retractions are publicized — i.e. they might change the title of papers, issue a press release if there was evidence of greater fraud, update metadata stores like CrossRef, issue a separate notice without modifying the original paper, etc.
Manually checking usually works but is not feasible for everyone, though this is something the RetractionWatch project does for retractions specifically.
At Scite, we have our own automated system for detecting editorial notices (including but not limited to retractions). Our data is a mix of information available in CrossRef, PubMed, and our own in-house process of identifying retractions and withdrawals based on the title modifications by publishers (we map out different prefixes and postfixes). You can read more about it in a preprint we published and find the associated public data we released as part of that.
This data is generally exposed in Scite in a number of ways. Our badge — which is freely available through our browser extension and also lives on a number of publisher pages — shows retraction information if we detected them for a paper.
Also, when you go to a Scite Report Page about an article that received a notice, we surface information about any notices it received by the metadata. Clicking on each notice pulls up the associated information, if available, so you can see e.g. why it received a retraction or correction and if that should affect your interpretation of the paper.
Since our users are often at different stages of the research lifecycle, we also have a feature called Reference Check that takes PDFs of a manuscript, extracts the references used, and orders them by most “problematic”, so you can see which ones are retracted or have many editorial notices, followed by most contrasted.
The goal is to show you the pertinent metadata about them and how you or your co-authors used that reference in the manuscript to make sure it was intentional.
Besides researchers, what kind of people use Scite?
Scite is used globally by anyone who reads or wants insights from research. That means undergraduate students, researchers at any stage of their career, publishers, bibliometricians, book authors, journalists, data analysts, funders, medical affairs teams, general users with an interest in a specific disease or therapy, and even other emerging startups. I think this is in part a reflection of the broad impact research has on our lives.
How do you recommend someone get started?
I think the easiest is to sign up for an account, activate a trial, and play around with our Citation Statement search and search some of your papers (or your friends, or a topic that excites you).
Then check out our new Scite assistant feature, which acts as a chatbot that queries ChatGPT and verifies its claims against our database of citation statements. Ask it any questions you want, from writing grant proposals to figuring out how many rats live in NYC.
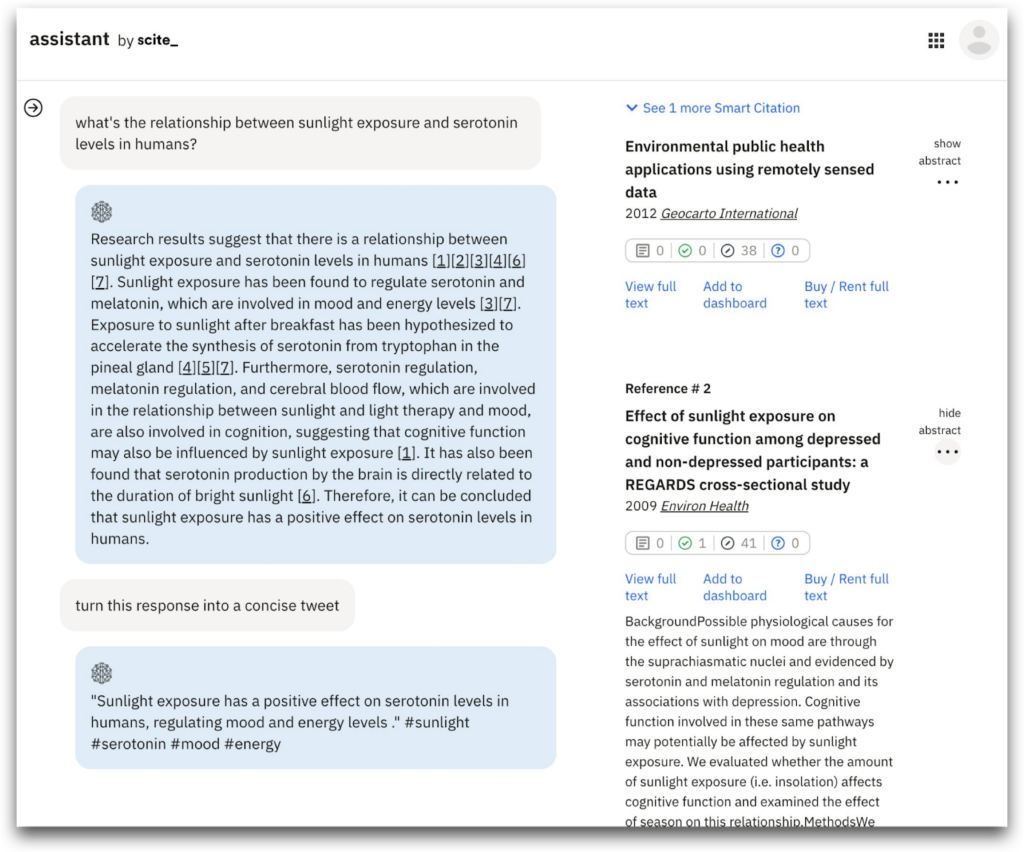
And really, you can get pretty creative here, since it’s not just restricted to life sciences. Finally, I’d recommend installing our free browser extension which makes it easy to see our information wherever you go.
And finally… What’s next for Scite?
At its core, Scite was always about improving the discoverability, reliability, and reproducibility of published works through our next generation citations. My goal has really been to see these next generation citations become more commonly used towards a positive benefit for everyone.
I think that Scite is in the middle of many exciting things — from a technological modernization in publishing, an understanding that numerical reductionism in citations doesn’t lead to the best outcomes, and advances in artificial intelligence — and there are a number of exciting applications of our unique data in all of these areas (and more).
Though we’re a small team and do our best to focus on high value features — like our search experience and our assistant — we’ve always tried to broaden the impact of our Smart Citations by partnering with companies wherever possible.
Five years ago, I couldn’t have predicted the features we’ve built today. I’m not sure I know what the applications will be five years from now. But I do know that our Smart Citations will power them.
Thank you so much for your time, Josh! Where can people learn more about Scite?
Thank you for hearing what I have to say! Scite is close to my heart and I would really encourage people to check us out at scite.ai. In particular, I think people may love our integration with ChatGPT, which you can find here. And you can follow us on our Twitter.