Welcome to this edition of our Tools for Thought series, where we interview founders on a mission to help us work better and happier. Michael Dubakov is the CEO of Fibery, an all-in-one workspace allowing the whole company to do everything together, whether it’s research, product development, marketing, customer management, and more.
In this interview, we talked about the proper metrics for productivity, how to augment organizational intelligence, what we can learn from hypertext tools from the 80’s, the benefits of combining work management and knowledge management, how to work with both structured and unstructured information, and much more. Enjoy the read!
Hi Michael, thank you so much for agreeing to this interview. Let’s start with a bit of a controversial question: what do you think is the problem with most productivity tools?
I’ll speak about teams’ productivity most of the time here. Productivity tools should increase productivity, right? But productivity of knowledge workers is extremely hard to measure. There is no good metric yet. Working hours, lines of code, or any similar metrics measure effort, but not results. We need a better metric.
I think the proper metric is the quality and quantity of insights. What is an insight? It’s a piece of new knowledge. It can take many forms: a new question, a new answer to an existing question, a new theory, a new proof, a new experiment, etc. The more insights a knowledge worker generates in a given timeframe, the more productive she is.
Most tools promote values like “save time”, “work faster”, etc. However, in the knowledge economy, we compete with knowledge, not efficiency. Our productivity tools should become knowledge management tools as well, thus making companies more intelligent.
The second problem is that productivity tools create silos. Wiki, Spreadsheets, CRM, Project management tools create many walls and barriers inside a company. As a result, it is much harder to extract and connect information. Connections are really important here, this is how we discover novelty. Data silos impede connections and impede insights generation.
These problems are extremely hard to solve and there is no tool on the market that does it, but at least we should embrace them and move the new generation of productivity tools into the right direction.
You are on a mission to augment organizational intelligence — what does that mean exactly?
Well, intelligence is hard to define. It is easy to understand de-augmentation though, Engelbart demonstrated it with a brick attached to a pen.
But what is intelligence augmentation? Engelbart defined it as “more-rapid comprehension, better comprehension, the possibility of gaining a useful degree of comprehension in a situation that previously was too complex, speedier solutions, better solutions, and the possibility of finding solutions to problems that before seemed insolvable.” Beautiful!
I define intelligence as quantity and quality of insights. This definition is shorter and includes everything Doug said. We need a tool that increases the probability of insights and quality of insights.
Conceptually, what would that look like?
There are many things here, but let me try to nail some important traits. First, I think that the knowledge management and work management dichotomy is false, we have to unite these spaces.
A dream tool should combine work management and knowledge management processes together. It should work very well with unstructured information that has poor meta-data (note, chat, text, document, diagram) and with structured information that has rich meta-data (task, product, protein formula).
Second, this tool should be a single point of truth about anything important happening in a company. It should break information silos, replace many tools, and fetch data from those tools it can’t replace.
As an example, a team usually uses different software for chat, task management and documents management. A dream tool should have all these things as features that are tightly coupled and work together with a single database.
Third, this tool should support connectivity. All information should be connected via all kinds of links (bi-directional links, relations, transclusions). It should be possible to build ontologies and transform unstructured information into structured easily. Interestingly, most organizations don’t try to connect data. However, true intelligence lives in connections, this is how we invent new things.
Finally, this tool should support information and process evolution. Teams and organizations evolve and processes change. However, most productivity tools are relatively rigid.
To summarize, we need a tool that accumulates, mixes, connects, and visualizes structured and unstructured information in a single space.
That sounds like a simple yet ambitious vision. Can you tell us how you turned these principles into an actual tool when designing Fibery?
Fibery is my second company. My first company was Targetprocess that I started in 2004. It was a software that focused on agile project management practices and was acquired by Apptio two years ago. So we learned a lot about companies’ processes and problems.
The most important problems to me were processes’ connectivity and evolution. We wanted to create a tool that connects many processes in a company and evolves with a company, but, to be honest, we completely missed the knowledge management part.
About two years ago I started to dig into the past and discovered many beautiful ideas. Surprisingly, hypertext tools from the 80’s were very powerful. They provided a unique environment to create, connect and share knowledge. For example, Intermedia tool was created in 1985 and it had bi-directional links, various visualizations and features we are reinventing last decade. The Internet killed all these systems, but now we have a renaissance of hypertext tools.
That is how we discovered that knowledge management is super important and unstructured + structured information mix is paramount for a real productivity tool for a knowledge economy.
Fibery is five years old already, but we nailed the current vision only a year and a half ago. The deeper we dig into it, the deeper we believe in it.
That sounds amazing. So, how does Fibery work concretely?
Fibery core is what we call a “flexible domain”. You can create your own structures and hierarchies that represent how your company operates. Basically, you can design your database, but it is well hidden from the creator. It means that Fibery supports structured information really well. Here is the very basic map of four processes:
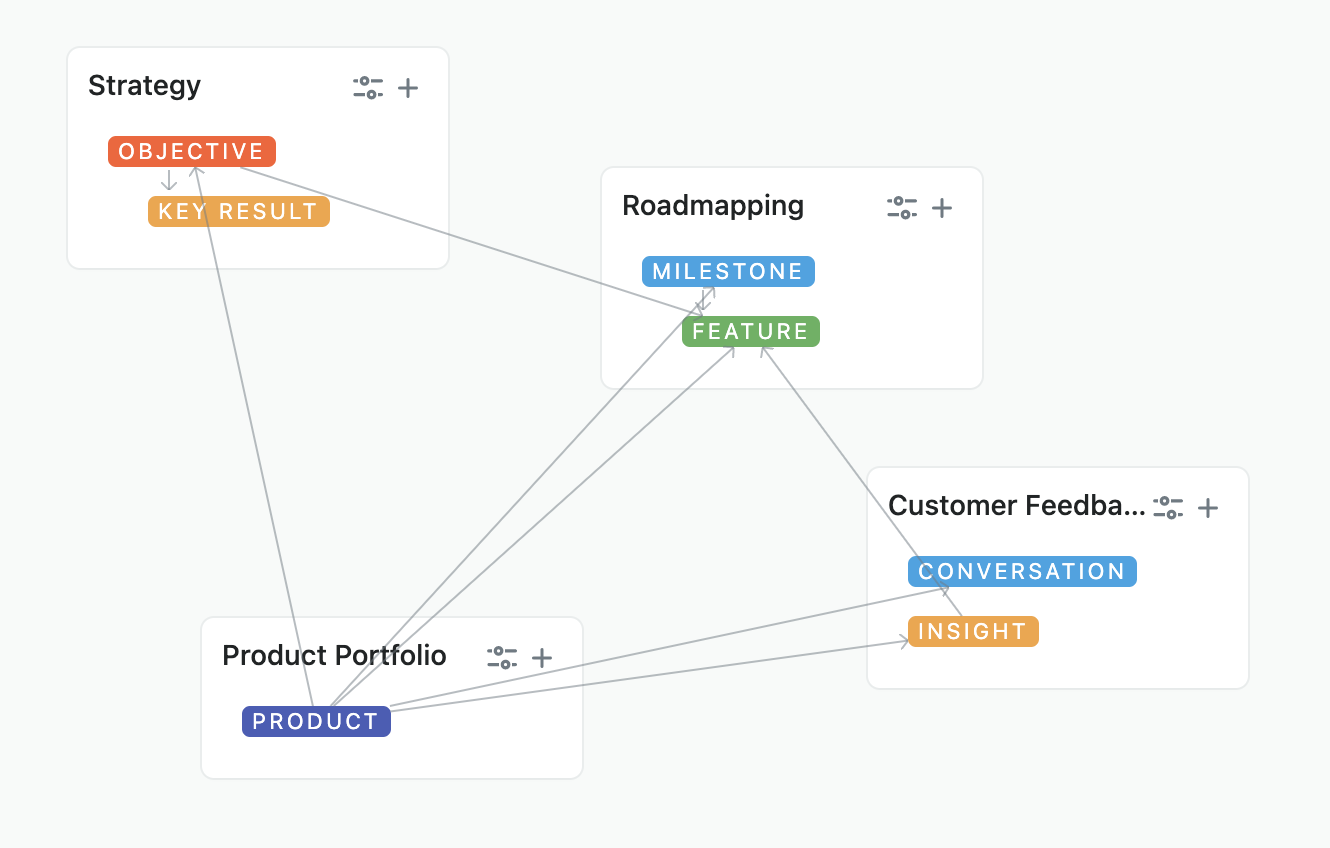
Then you have all kinds of visualizations. You can visualize data using several Views: Timeline, Board, Table, Hierarchical List, Calendar, Graphical Report.

Then we have tools to work with unstructured information (Documents and Whiteboards). Our documents are kinda tricky, we combine them with databases in an unusual way, so you have a rich edit document in every entity in a database. Whiteboard View mixes databases and free form diagrams, you can include entities from the database and do cool things.
And we pay much attention to links. Connections and linking information is where Fibery really shines. You can select a part of text anywhere and connect it to any entity via a bi-directional link. You can connect databases via strong relations and build deep hierarchies and complex data structures. It all helps people to discover new things. Fibery has a relatively unique panel navigation, so you can quickly explore these links and get back without losing focus.

Then you want to bring the data from external systems. Fibery power is that you can replicate any domain. You can fetch data from dozens of systems (Intercom, GitLab, GitHub, Airtable, Braintree, Zendesk, etc) and connect this data to other databases. For example, you can fetch Pull Requests from GitLab and connect them to Features, or you can fetch Subscriptions from Braintree and connect them to Accounts.
Finally, you can automate things in Fibery, it has automation rules and buttons. It helps to keep data consistent and, well, save time.

These sound like powerful workflows! What kind of people use Fibery?
Fibery is a horizontal product, but we are mostly focusing on product development companies and startups now. Our largest customer has 500 people in Fibery and uses it for all kinds of processes, from product management to legal.
Our typical customer is a product company or a startup below 100 people that uses Fibery for everything: product development, CRM, feedback accumulation, HR, strategic plans. We have more than 250 paid customers already.
And how do you personally use Fibery?
As you can imagine, we use Fibery for all our processes. In fact we have only two major tools: Fibery + Slack. Eventually we want to get rid of Slack and add sync communication in Fibery.
My favorite use case is feedback accumulation and prioritization. We have several channels of feedback: Intercom, customers’ calls, community forum, and some random suggestions in other places.
Fibery integrates with Intercom and Discourse, and fetches all communication. Thus we can easily highlight a part of text and link it to some Feature, Bug or Insight in Fibery. We write notes for every call and do the linking afterwards, here is how it looks:
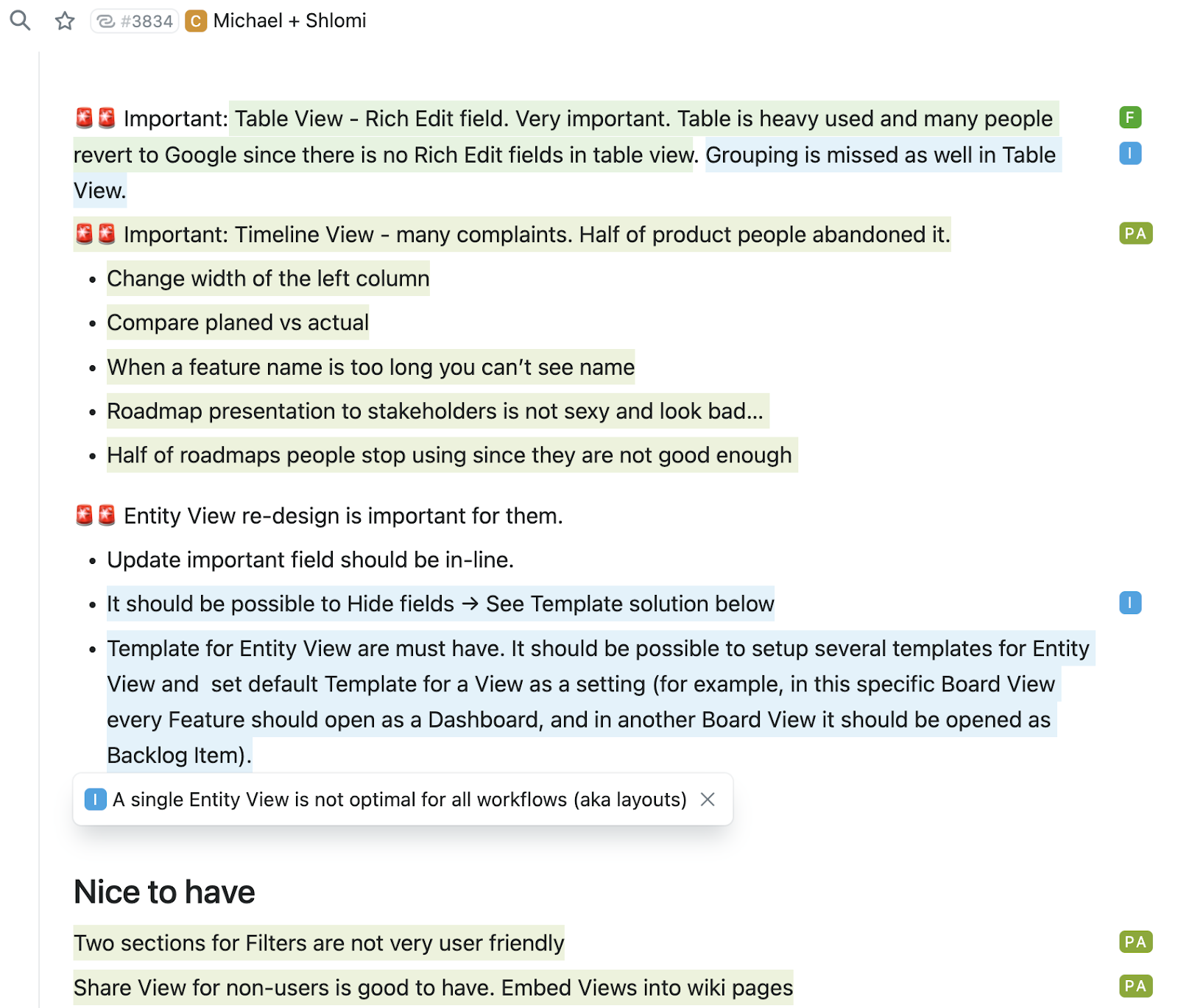
The best thing is that these links are bi-directional. When you navigate to some feature, you will find all the feedback inside linked to it. Eventually feedback accumulates and you can create a list that shows what features or insights are requested by customers and leads more often. It helps to decide what to take next into development. From my experience, feature prioritization is one of the hardest processes for product managers, and Fibery solves it.
Another cool use case is that we use Fibery as a CRM. All registered accounts are added into Fibery, we also have an integration with a paid processor Braintree. So we track all payments in Fibery and can create charts to measure MRR, LTV and other metrics, see what niches convert better (that is how we discovered that product teams get more value from Fibery), and see what marketing channels work better. This connectivity just makes everything so much easier!
Finally, we moved the Fibery user guide into… Fibery. You can publish spaces. Initially we used Intercom for the user guide, but it was a painful experience. Intercom text editor is a nightmare, you have to login into it to update any article and it was just an additional cognitive load.
When we moved the user guide into Fibery, everything became so much simpler. If you need to correct something, just type the name of the guide article, navigate into it and do the correction. Moreover, internally all guides are linked to Product Areas, so they are easier to find and it is easier to spot what guide is missing.
How do you recommend someone get started?
Fibery is a relatively complex system. You have to learn the main building blocks to build your own process and get a real value. We advise people to be patient and start from something simple, like 2-3 connected processes.
Usually there is a single person who builds first spaces and only then invites teammates. This is a good idea, since collaborative workspace building is possible, but only for the skilled people who are already fluent in Fibery.
Fibery shines when you have several processes that are connected. For example, product development, software development and feedback accumulation. These processes are highly interconnected, so when you link feedback to features, create tasks from features and plan development iterations, Fibery starts to deliver true value.
And finally… What’s next for Fibery?
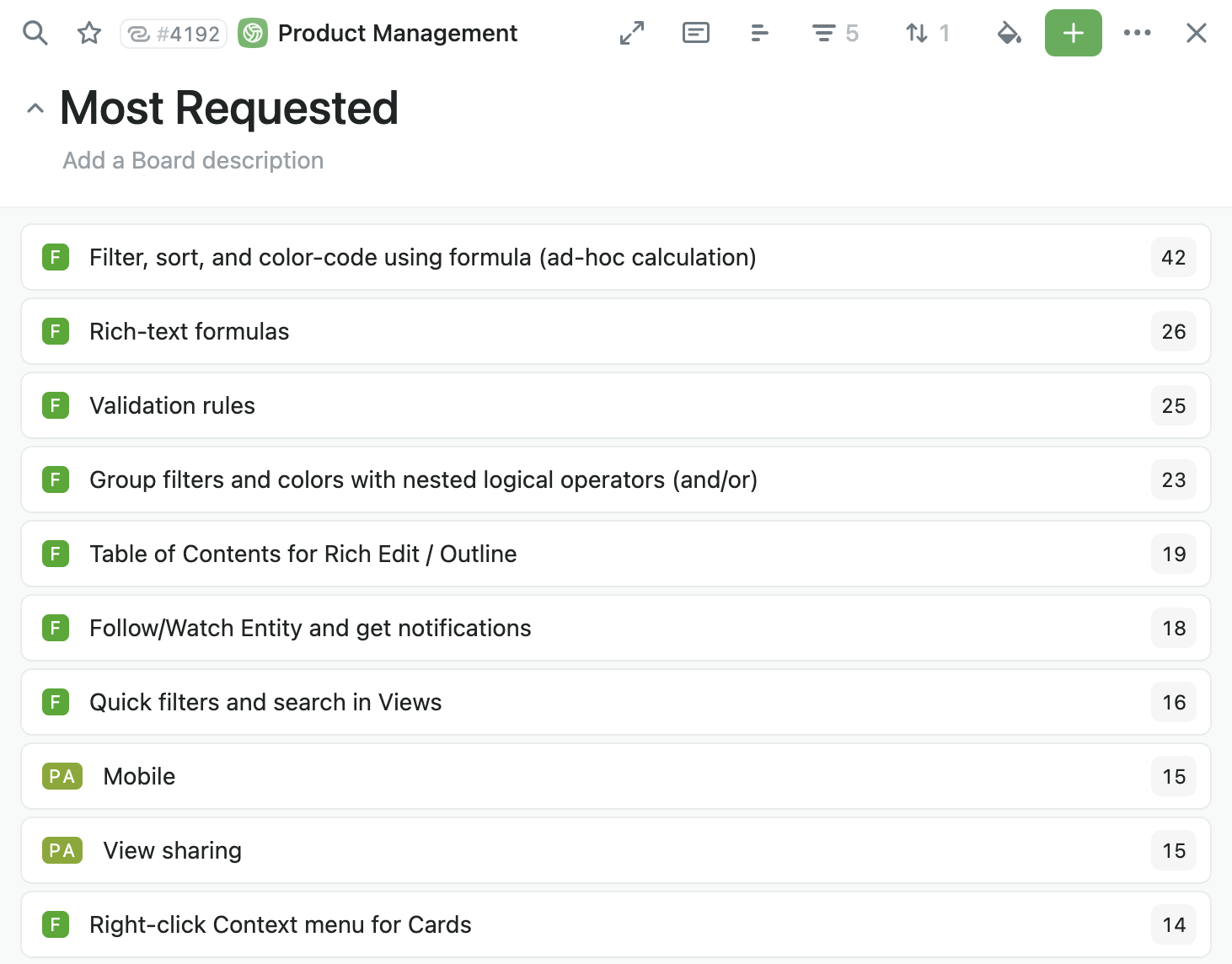
We are following our vision and there are several missing things in Fibery that we are focusing on right now. You can follow our roadmap, it is public.
First, we are working on granular permissions and access. In every company you want to hide some information from some people to manage cognitive load. Granular permissions in a flexible system is not an easy task, since we don’t have stable entities like Project or Team in other systems. I think we nailed the concept and will start implementation soon.
Another important area is documents. We are moving to a block-based editor and want to give people more options to mix structured and unstructured information. For example, we will allow users to insert views (board, timeline, report, etc) into Fibery documents soon.
Finally, we want to get rid of Slack and think about how to merge sync and async communication into Fibery.
Thank you so much for your time, Michael! Where can people learn more about Fibery?
Sure, check Fibery website to learn more about the product, our blog has some really good articles and I post monthly about our progress. You can also follow us on twitter.