Welcome to this edition of our Tools for Thought series, where we interview founders on a mission to help us make the most of our mind. Alan Chan is the co-founder of Heptabase, a visual note-taking tool that helps you learn complex topics.
In this interview, we talked about the inherent dilemma of intelligent product design, how to create a co-evolution system to address this dilemma, the five parts of the knowledge lifecycle, how to solve interoperability across use cases with meta-apps, how to support both individual and collective knowledge creation, and much more. Enjoy the read!
Hi Alan, thanks so much for agreeing to this interview. Let’s start with your vision. You want to build a truly universal Open Hyperdocument System. What does that mean?
Our vision at Heptabase is to create a world where anyone can effectively establish a deep understanding of anything. And this universal Open Hyperdocument System (OHS) is a means to that vision. It’s hard to explain what OHS is without context, so I’d like to first share the story of how I encountered this concept.
So, one of the most enjoyable things in my life is learning things that are interesting to me. In middle school, that thing was math. In high school, it’s physics. That’s why, when I went to college, I double majored in Physics and Mathematics.
One thing that I really appreciate in these disciplines is how one concept in Mathematics can be applied to so many different areas of Physics, and one theory of Physics can explain so many phenomena in the world. There were many moments when I started to understand how all these things are interconnected and how things are simple yet complex at the same time. That’s what I mean by “deep understanding.”
In my sophomore year, I wanted to spend more time exploring other disciplines such as history, psychology, computer science, business, and many others. I had this fundamental desire to make sense of everything in the world, and I wanted to try my best to read as much as I could and see how far I could get.
So, I dropped out of college and bought a lot of books to read and started building my own knowledge system to manage all the reading notes I wrote. I used Evernote for a while and switched to Notion a bit later, and I immediately noticed that Notion has many interesting and powerful capabilities.
I looked into Notion’s website and found these big names in HCI: Douglas Engelbart, Alan Kay, Ted Nelson, Bret Victor, etc. I read and watched everything on Bret Victor’s website. I read most of the things on Doug Engelbart Institute’s website, including the Augment Human Intellect report. I read a lot of Alan Kay’s essays, Ted Nelson’s Literary Machines, and Seymour Papert’s Mindstorms. And then I read this mind-blowing book called The Dream Machine, which I still think is the best book about computer history.
After reading all this stuff, one thing that inspired me the most was how these computer pioneers and thinkers think about how humans and computers can work together to solve complex problems.
For example, Engelbart has this approach of using computers to improve the collective IQ of a group of people. What he’s suggesting was building a new kind of tool called Dynamic Knowledge Repositories (DKRs) that can integrate and update the latest knowledge from a group of people, and all the DKRs in the world will be powered by the same Open Hyperdocument System (OHS).
That caught my attention, so I looked into the specs of OHS, and then I noticed that its capabilities look so much like Notion. Then I realized what Notion did was they implemented many of OHS’s specs and wrapped it with a modern UI and sold it as a team collaboration product. But fundamentally, it’s very similar to Engelbart’s OHS specs.
So, the next thing that came to my mind was: why implement an old spec from the late 20th century? How will Engelbart design OHS if he lives in the 21st century and is familiar with all the computer technologies we have now?
Engelbart’s intention was to augment human collective intelligence, and I think modern digital collaborative workspaces are still far from that. The original OHS system doesn’t seem to address much about the process of how humans discover and distill knowledge and foster deep understanding on different topics, and which part of the process happens independently and which part happens collectively.
Thinking about this was intellectually stimulating, and this question had been on my mind for a few years. And that was the time the idea of Heptabase started to take shape. I wanted to design and create a new Open Hyperdocument System in the 21st century that serves as the foundation of all modern knowledge repositories.
Everything built on top of this system should have the inherent capabilities to empower people to effectively create a deep understanding of anything they’re learning and researching.
What a journey. Why do you think this vision is so challenging to bring to life?
I think the most challenging part is that you’ll face this dilemma between building a system that is general enough to become the foundation for many things, and building a product that is useful enough for end-users to solve their problems.
One thing I’ve seen many companies do is to begin by considering what a perfect system would look like and what capabilities it should have. They write clear specs for that system and then build everything based on these specs. The biggest challenge of this approach is that you end up with a Swiss knife that has a wide range of capabilities, and while it might be able to do many things, it can be intimidating for end-users.
Most people just want to find a solution that solves their problem out of the box. Most people don’t care about all the concepts and capabilities you introduced in your system. And no matter how good your technology is, if not many people use it, you’ll end up going nowhere. So, these companies usually have to spend a lot of time working on improving usability, simplifying their product, and understanding their users’ needs.
Personally, I prefer the approach of fostering a “co-evolution” process between the design of the system and the users’ jobs to be done. This is another important concept from Engelbart, in which he used to describe the back-and-forth process of how humans evolve with the tools they use and how tools evolve with the humans using them.
One great example of such a process is Bret Victor’s project called Dynamicland, which I think of as an environment where people can explore and understand systems and have data-driven conversations through authoring dynamic visual representations of data. The system includes a lot of paper cards that contain programs, and a protocol that enables people to make claims and wishes on these cards to facilitate communication across programs.
What fascinates me is how they built the system—they invited many people with different backgrounds to come to Dynamicland and observe how these people interact with Dynamicland, and then use such learning to evolve the design and the protocol of the entire system.
So, the biggest difference between these two approaches is how much you believe you know and how much you believe you don’t know. If you think you know everything, then you design the entire system from the beginning, and the risk is that you might be wrong about many things.
If you think you know just a few things, then you start by designing a system that handles these few things well, put it out and see how people use it, gain more knowledge on how people work, and use this knowledge to evolve your system to accommodate more capabilities while taking care of usability.
The most challenging part of this approach is to resist the urge to try to design a perfect system from the start and admit that there are still things you don’t know. Once you admit that, you’ll start thinking about how you can acquire those insights from your users.
So how is Heptabase approaching this?
When building Heptabase, there are some mental models and guiding principles that I have been using since the very beginning.
The first mental model is called “The Knowledge Lifecycle”, which consists of five parts: exploring, collecting, thinking, creating, and sharing. We want to ensure that knowledge can be seamlessly passed from one part to another, and we want to ensure that for each part of the lifecycle so we can design and build a great solution that addresses the problems people face really well. In the end, it’s all about whether we can create this synergy across all five parts of the cycle. We have been working on the “thinking” part since 2021, and then the “collecting” and “creating” parts since 2023, and will work on the “sharing” and “exploring” parts in 2024.
The second mental model is system layering. The way I abstract the system we’re building is that there will be multiple independent layers, each focusing on one unique job. For example, a contextual layer for preserving thinking context, a descriptive layer for managing categories and adding properties, an annotation layer for annotating static files, an integration layer for creating aliases for third-party data, a communication layer for enabling a group of people to construct a deep understanding of complex topics, and an application layer for users to build card-based software on top of our system in the future, and so on.
So when many users request a feature, the first thing I think about is which part of the knowledge lifecycle it belongs to and how we can design and integrate this feature with our existing solution in this part of the lifecycle.
The second thing I think about is which abstraction layer this feature belongs to, so I can have a clear picture of how the system design is evolving. On the other hand, sometimes we reach a point where we believe we have done great work in building one abstraction layer and want to shift our focus to building the capability of the next abstraction layer. I will then consider which part of the knowledge lifecycle this capability can be useful for and how it can solve real-world users’ problems. The process of switching between these two mental models while building the product is what I mean by “co-evolution.”
And then, in execution, there are two major guiding principles. The most important principle in our company is that we want to ensure that everything we’re building is aligned with our ultimate goal of helping people acquire and establish a deep understanding of the things they care about. We’re very conscious of not getting distracted by other purposes. The second principle is that we want the product to be as friendly and intuitive as possible. Our target users should be able to get into the flow of thinking as soon as they open the product.
It’s great to hear that you have solid foundational mental models underlying the product vision. Now, tell us: how does Heptabase actually work?
At this moment, you can think of Heptabase as a visual note-taking tool that helps you learn and research complex topics. We currently only focus on the individual use case because we want to make sure everyone is first equipped with the best tool for independent thinking before we build the communication layer for collective thinking.
So, the current product focuses on solving the problem in the collecting → thinking → creating parts of the knowledge lifecycle. Most users use Heptabase to digest complex literature, integrating this knowledge with their own ideas to create high-quality outcomes.
Like I mentioned previously, in 2021-2022, we primarily focused on the “thinking” part. During this time, we built a whiteboard specifically designed for empowering complex knowledge work, rather than just drawing and brainstorming.
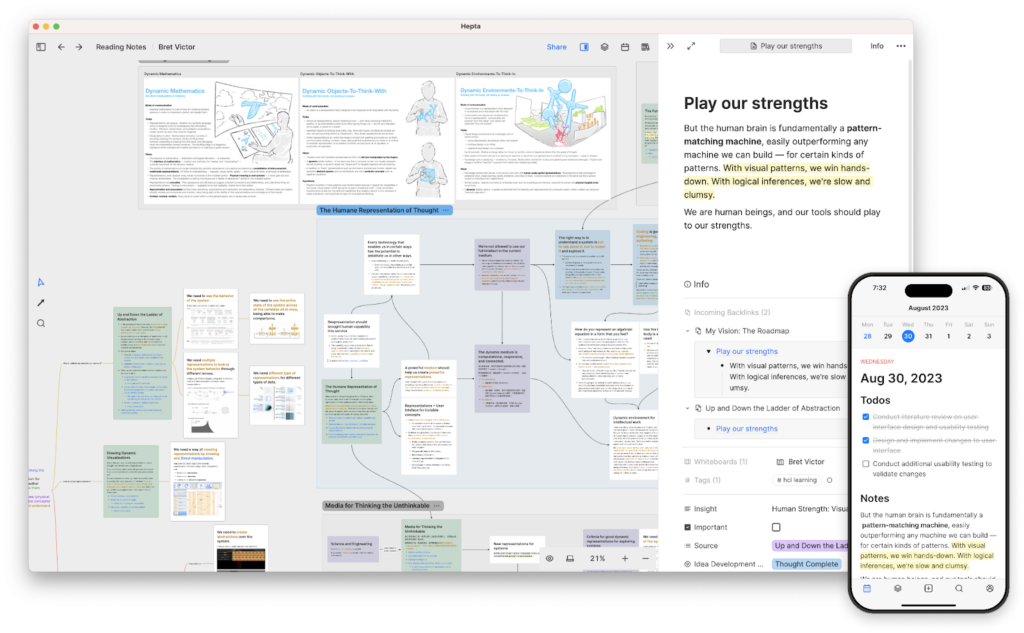
Heptabase’s whiteboard is designed with two insights. The first one is obvious: humans think much better when they think visually. The second one is less obvious: to gain a deep understanding on a topic through visual thinking, you need to first atomize the concept you learned. Real deep understanding doesn’t come from the “relationship between two books” but from the “relationship between all the concepts in these two books.”
That’s why in Heptabase’s whiteboard, you can easily break down lengthy card notes into atomic concept notes. I believe this process of “extracting concepts” is the real foundation of deep understanding.
Once you break down these concepts, you can use sections, mind maps, nested whiteboards, and many other features we have built to make sense of them and even reuse a concept across whiteboards. If you want to learn more about how this process works with real-world examples, I recommend checking out an article I wrote titled The Best Way to Acquire Knowledge from Readings.
In 2023, we allocated more resources to improving the “collecting” part of the knowledge lifecycle. Apart from the obvious tasks, such as launching mobile apps and web apps on all platforms, a significant amount of work here focuses on helping you collect knowledge from different types of sources. For example, you can bring PDFs, audios, videos, images, and Readwise highlights into Heptabase. For PDFs, you can perform the exact same process of “extracting concepts” by creating highlights and annotations and dragging them onto the whiteboards.
In the next few months, we’re going to let you extract concepts from audios, videos, and images. If you open a browser side by side with Heptabase, you can also drag contents from the web to Heptabase’s whiteboard and turn them into cards. Essentially, we want to ensure that you can extract concepts from any type of knowledge sources and build your library of concept cards, so you can reuse and apply all the knowledge you’ve learned anytime you want.
It’s hard to cover everything on how Heptabase works here. So, if you want to learn more, you can check out our public wiki.
What about the interoperability of the information you store in Heptabase? This is a complaint many knowledge workers have with modern tools for thought.
Before discussing how Heptabase thinks about interoperability, I want to first share how most other companies think about it so you can see how we think differently. There are two common ways to think about interoperability. One is the interoperability across use cases, and the other is the interoperability across applications.
The common approaches to solving interoperability across use cases are either building an all-in-one product that can accommodate many use cases through customization, or allowing third-party users to build feature-level plugins on top of your product, so that you can install multiple plugins to add features for your specific use case.
Both approaches will introduce complexity and increase the learning curve of the product. While there are many people who love customizing their system, there are also many people who hate it because they do not want to learn and set up a whole bunch of things just to get simple work done.
As for the interoperability across applications, there are also two common approaches. You either use APIs to expose your data for another app to use, or use a common file format another app can read, like Markdown. Both approaches have their own problems.
In the API approach, you need both apps to have APIs and build integrations to make the data interoperable. You can never guarantee that it will happen. In the Markdown file approach, you’ll notice that there are tons of features that Markdown doesn’t support, so people will add extra metadata on top of these Markdown files to support those features. And if you open these files with different apps, they still won’t know how to handle this metadata, or they might handle it differently and break things, as there’s no common protocol on what you can read and write to those files.
So, the way I think about how we can solve the problem of interoperability across use cases and across applications is that I want Heptabase to eventually become a system where people can build and launch their own “meta-apps” on top of it. Although we don’t allow third-party developers to build meta-apps at the moment, we have already built six native meta-apps inside Heptabase. These meta-apps are not database templates or feature-level plugins that provide new views for existing data. They are service-level applications with their unique UIs, workflows, and features that help you deal with a specific use case.
The cool thing about meta-apps is that they all run on top of “cards” which are the primitives of Heptabase’s system. We currently have note cards, journal cards, PDF cards, and will soon introduce highlight cards, audio cards, video cards, image cards, and more. These cards are interoperable across meta-apps, and every meta-app will read and write application-specific metadata on these cards, following the same protocol.
With this approach, Heptabase is essentially an OS for meta-apps and a browser for cards at the same time. And the benefit is that we can reduce the complexity of trying to install a lot of feature-level plugins or set up a lot of properties and views just to deal with a simple use case. We also don’t need to waste time building API integrations between meta-apps.
And of course, there will still be times when you want to connect Heptabase with applications that are outside of our ecosystem, so we still support exporting all data into Markdown + YAML format, and will eventually have our APIs for others to use. But I think over time, as the entire meta-apps ecosystem grows and matures, there will be fewer needs for that.
Another challenge is to support both individual and collective knowledge creation.
Definitely. Although we’ve been focusing on the individual learning and research process since 2021, collective research is one of the major problems that we plan to tackle in 2024. It is important because most important problems humans have solved, we have solved them collectively. We have to put together knowledge puzzles that were scattered across people’s brains.
The tricky thing about modern solutions for collective research is that people seem to believe that all you need is a collaborative workspace where a group of people can edit and connect documents together. Solutions like this are great for building a wiki or ensuring that people are aligned on a project, but I think it doesn’t really address the core problem of collective research, which is how everyone’s input on a topic can gradually lead to a deeper understanding of that topic for everyone.
It’s obvious that you need a place where everyone can contribute their knowledge and ideas. The non-obvious part is how to structure this information in a way that can avoid groupthink, direct your attention to things that are useful to you, ensure that everyone can still perform independent thinking processes while leveraging the knowledge others have contributed, and facilitate the discussions that can lead to establishing a deeper understanding of the topic. These are some of the problems that we’ll be working on when building a communication layer on top of Heptabase.
There are two core ideas on how we plan to address this problem at the beginning. The first is to create a back-and-forth process between personal workspace and collective workspace, so people can still have their own independent thinking process. The second is to help people in the collective workspace to create objectives, structure these objectives, and create different representations for the same objectives using their collective knowledge. Designing this will be a huge challenge, and I don’t think we can get it right in the first version. What we will do is conduct internal testing and see how it works for the entire Heptabase team. Then, we can involve more community members and gradually open it up to more people.
What about you, how do you use Heptabase?
I mainly use Heptabase for learning, research, planning, and writing. Every morning, I’ll first open my journal and see the tasks I need to do for that day. There will be a bunch of to-dos that I wrote or assigned a few days ago. Let’s say it’s the end of the month and I need to write an investor update. I also want to research the design of this new product feature, spend some time on the growth strategy, and read another chapter of the book I’m currently reading.
One of my favorite features about Heptabase is that whenever I open a whiteboard, a card, or a tag, I can open them like a browser tab on my left sidebar. I can pin the tabs that I commonly visit and create tab groups for different types of work.
For example, I want to first write that investor update. I’ll go to the “Company Operation” tab group, open the #investor-update tag, and create a new card to start writing. While writing, I might search for and open some existing cards on the right sidebar as a reference.
After I finish writing, I’ll check the to-do in my journal and move on to product research. I’ll go to the “Product Research” tab group, open a pinned whiteboard called “Better Collecting → Thinking” which has all my product ideas and user insights on this problem. I might add some new ideas, stare at them, rearrange them, group them, and refine the whiteboard structure until I feel like I have a better understanding of this problem. Then I’ll write a feature specification using the ideas on this whiteboard and send that spec to the designer for feedback.
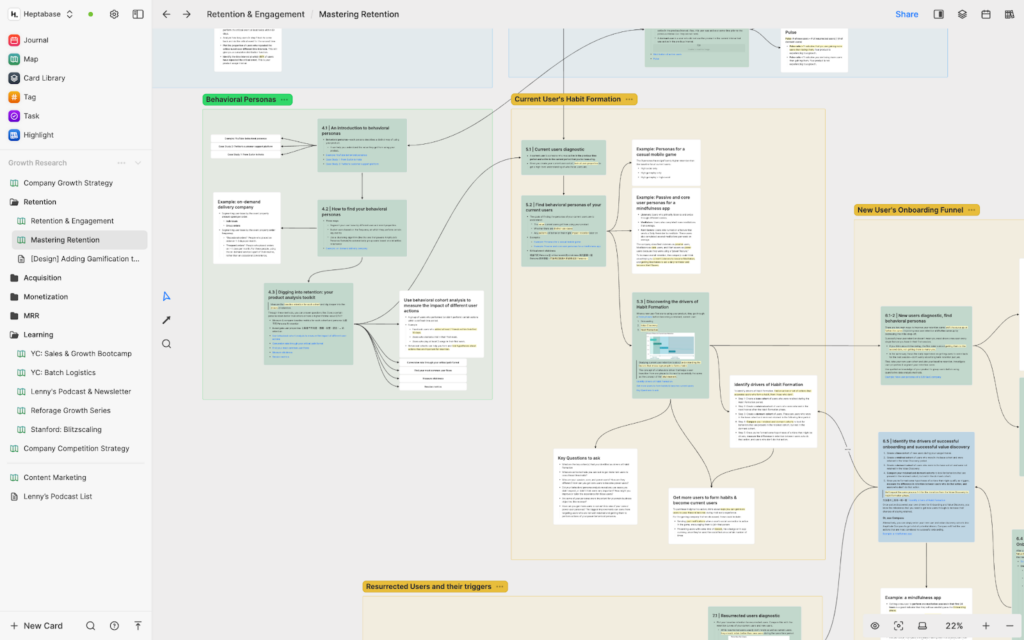
Once done, I’ll check the to-do list in my journal and go to the “Growth Research” tab group, and open the “Retention & Engagement” whiteboard. I have clipped several long articles from the web in that whiteboard, and I will break these long cards into smaller concept cards, rewriting the knowledge I learned in my own words. The title of each concept card is usually a sentence, and the content consists of supporting arguments and evidence
One thing I love doing is reading a lot of articles, distilling the knowledge, and forming my unique understanding on the whiteboard using the knowledge I’ve gained from all these articles. Then, I devise the growth strategy based on this understanding.
Now that I’ve completed all the work for today, I’ll go to the “Personal Learning” tab group, and open the “Reading Notes” whiteboard. Let’s say I’m reading this book called Innovator’s Dilemma, and I’ll have a sub-whiteboard for it with the book title as its name. In this sub-whiteboard, I also break down all the knowledge I’ve learned from this book into concept cards.
Assuming today I’m reading this chapter about competition in the hard drive market, and I create many concept cards about it. This reminds me of other concept cards that I created for other books that are also about competition. So another thing I love doing is that I might create a whiteboard called “Competition Philosophy,” and then import all the concept cards I have about competition from the “Innovator’s Dilemma” whiteboard and other books’ whiteboards like Zero to One, The Art of War, and Chip War.
This is something that I’ve done a lot in Heptabase, which is essentially creating whiteboards on different topics, and reusing the concept cards that I extracted from different books, articles, videos, and PDFs for these topics’ whiteboards and gradually forming a deeper understanding over time.
How do you recommend someone get started with Heptabase?
I think the best way to get started with Heptabase is simply to find a topic or a book you’re interested in and create a whiteboard for it.
For example, if you’re interested in Deep Learning and there are these three long articles that you want to read, you can open the articles side by side with Heptabase and extract content to Heptabase’s whiteboard to create concept cards. Each concept card should contain an idea that you think is important.
The “aha” moment of Heptabase is that you gradually accumulate more and more cards from more and more sources, and you’ll find the sense-making process on the whiteboard very smooth. You will find it very easy to get into the flow of thinking, and several hours later, you’ll have formed this unique understanding of the topic. You will know what you’re going to read next, how you’re going to integrate new knowledge with existing knowledge, and you will know that this understanding will be stored visually here forever.

And finally… What’s next for Heptabase?
In the next quarter, we have three priorities. First, as I mentioned earlier, we want to introduce more types of cards, especially multimedia, and allow users to highlight, annotate, and extract knowledge from these different types of cards. The second priority is to build a communication layer on top of Heptabase to enable the collective research process. The third priority is to upgrade our backend infrastructure as we are now facing a much larger user scale than in 2022.
And of course, we will continue to refine and improve the experience of existing features like whiteboards, cards, and tags, which are the foundation of everything we have built. In the end, it all points back to our vision, which is that we are doing everything we can to create a world where everyone can effectively establish a deep understanding of anything.
Thank you so much for your time, Alan! Where can people learn more about Heptabase?
You can try out Heptabase from our website. The best place to learn more about it is our public wiki. If you want to learn about our philosophy, I recommend reading My Vision – The Roadmap and The best way to acquire knowledge from readings. If you just want to learn about how the current product works, I recommend checking out Getting Started with Heptabase and Heptabase 1.0. We have an active Discord community with more than 12,800 members that we welcome you to join. We also occasionally share some product updates on Twitter (X).